
Finetuning Protein Language Models
Contrastive Fitness Finetuning and FSDP

What is Finetuning?
In this post, I want to share some results and thoughts on finetuning protein language models. Finetuning is a powerful technique to get more out of foundation models. For example, finetuned models can perform better at specific tasks like sentiment detection or medical diagnoses compared to the original foundation model. This technique is especially useful for directed evolution (DE) in protein engineering. DE, a Nobel-winning technique, has helped turbo-charge protein engineering for the past 3 decades, and is an iterative paradigm coupled with empirically testing designed variants in the lab.
ProteinGym: Data for Finetuning Protein-Language Models
Finetuning of language models for a specific task depends on task-specific data being available. In the case of protein-language model finetuning, these data could be related to the properties of a protein(s), such as activity, stability, or binding. Proteingym.org. Proteingym catalogues several datasets relevant for protein engineering and also helps benchmark some of the commonly used protein-models against these datasets. I will only refer to the Deep Mutational Scanning (DMS) dataset going forward, but please check out Proteingym.org for other types of data that are available for benchmarking.
Finetuning ESM-1v Model
Contrastive Fitness for Finetuning Protein Language Models (ConFit):
I’ve followed the excellent ConFit paper by Junming Zhao, and Chao Zhang from Yunan Luo’s group at Georgia Institute of Technology to help with the finetuning process. This paper borrows inspiration from the Reinforcement Learning with Human Feedback (RLHF) technique, where ChatGPT style language models are finetuned using human feedback in the form of text A is better than text B, instead of assigning a specific metric to each text. Using this RLHF technique of contrastive learning, the authors of ConFit turn the protein-language finetuning problem into a relative ranking problem:
Each protein variant’s log-likelihood is the sum of log-likelihood differences of a mutated amino-acid compared to that residue’s WT amino-acid:
\(\hat{y}_\theta(x^{MT}) = \sum_{i \in M} log p_\theta(x_i^{MT}|x_{-M}) - log p_\theta(x_i^{WT}|x_{-M}) \)In the above equation, xMT is the protein variant with M amino acids mutated compared to the WT protein xWT. x-M is the protein sequence (MT or WT) without the mutated residues (i.e. the mutated residues are masked from the ESM-1v model). And pθ is the log-likelihood estimated by the model with parametrized by θ, for example ESM-1v in our case.
If we have a protein i better than protein j based on experimental fitness or activity values, then we want the model’s predictions yθ for protein i be higher than the predictions yθ for protein j. This is captured using the Bradley-Terry (BT) loss function shown in the following equation, where the model is trained to predict the ranking of the protein variants from the original training data.
\(\textit{L}_{cal} = \sum_{y^i > y^j} log [1 + exp(-[\hat{y}_{\theta}(\textbf{x}^i) - \hat{y}_{\theta}(\textbf{x}^j)])] \)Using the above equation, any model that predicts the log-likelihoods of i to be lower than j will be penalized.
By predicting the likelihoods and the associated rankings instead of the original fitness values, the finetuned model is protected against catastrophic forgetting. Catastophic forgetting is where the original model after finetuning on one task or dataset performs worse on some other tasks or datasets. This happens when the finetuning task is “misaligned” with the original pretraining task. In the case of ESM-1v the pretraining task is to predict the likelihoods of the masked residues, which is the same as our finetuning task
Regularization is also performed to guard against catastrophic forgetting. The ConFit authors employ regularization by limiting the KL divergence of the finetuned model from the original model:
\(\sum_{i } p_\theta(x_i^{MT}|x_{-i}^{MT}) log \frac{p_\theta(x_i^{MT}|x_{-i}^{MT})} {p_{\theta_0}(x_i^{MT}|x_{-i}^{MT}) }\)In the above equation, pθ is the finetuned model and pθ0 is the original model. We will see an example below of why this regularization may be important. For the results I will show you later, I turned off this regularization loss
FSDP for Finetuning:
We have the data for finetuning and the model, but we still need one more thing: GPUs! Unfortunately, most language models need GPUs with a lot of memory and it gets pretty expensive pretty fast to use these “data center” GPUs like H100s and A100s. One way to get around this problem is to use multiple GPUs with lower per-GPU memory . This is even more enticing if we can use consumer GPUs like RTX4090. However, we need a way to break up the model and the data across these multiple GPUs, and this is where Pytorch’s FSDP is a lifesaver. At a high-level, FSDP allows us to “shard” the different layers of a model across different GPUs, do the necessary calculations by communicating with other GPUs, and release the copied over data post-calculations. This leads to some overhead in communication between the GPUs but the benefits of the larger total memory that is now accessible are huge.
There are several libraries that are geared towards helping us finetune models:
Unfortunately, all of these are meant for text-based and mostly causal language models like Llama and GPT. I wanted something a bit more flexible to deal with masked models like ESM-1v. I landed on using FSDP-QLoRA from Answer.AI which simplifies the finetuning code into one simple script. And as a bonus this script can finetune quantized LoRA called QLoRA. Read this excellent blog post from Answer.AI about the philosophy behind why and how they created the FSDP-QLoRA repo. However, this script still is tied explicitly to training Llama or other causal models using text data.
Some modifications I had to make on top of the FSDP-QLoRA script
Modify the model-wrapping function to accept the ESM-1v model and other masked models in addition to casual language-models
The dataloader to accept the protein variant data
In addition, I had to modify the forward pass to deal with the ConFit specific part. This last point warrants a bit more context. The contrastive fitness as implemented in the ConFit compares scores of protein sequences only on the same GPU and when data is split across GPUs, not all comparisons will be made for each batch of proteins. Thankfully, in large-language model research if you search long enough you will find that someone already ran into the problem you ran into and have a solution for it 🙏🏻. That is the case here as well: DisCo-CLIP to the rescue! DisCo-CLIP’s gather function allows us to gather gradients from all GPUs into any one GPU and average these gradients to perform back-propagation within the specific GPU. I used the same technique to gather scores across all GPUs into any one GPU to calculate the loss within each GPU which is then back-propagated on that GPU. The function for doing that for the Bradley-Terry loss in ConFit is here
LoRA vs DoRA
There are several different techniques to finetune a large language model. But Low-Rank Adaptation (LoRA) is the most popular and that is what has been used by authors of the ConFit paper. At a high-level, LoRA adds the inner-product of two low-rank matrices to the existing weight matrix to “finetune” the weights for a given dataset. This technique is computationally cheaper than directly updating the full weight matrices and has shown good performance across multiple benchmarks. Another variant to LoRA called Weight-Decomposed Low-Rank Adaptation (DoRA) has shown to be better in some cases. In this work, I tested out both but did not see any major differences in the results between them
RunPod for Cloud GPUs
To use consumer GPUs there are now several cloud providers. I chose runpod for its simplicity and availability of RTX4090 GPUs. I tested the setup using 2 RTX4090s (24 GB memory per GPU) and 2 Ada6000 (40 GB memory per GPU).
Results on Three Protein Datasets
Case Study 1: ARGR_ECOLI_Rocklin_2023_1AOY: LoRA vs DoRA
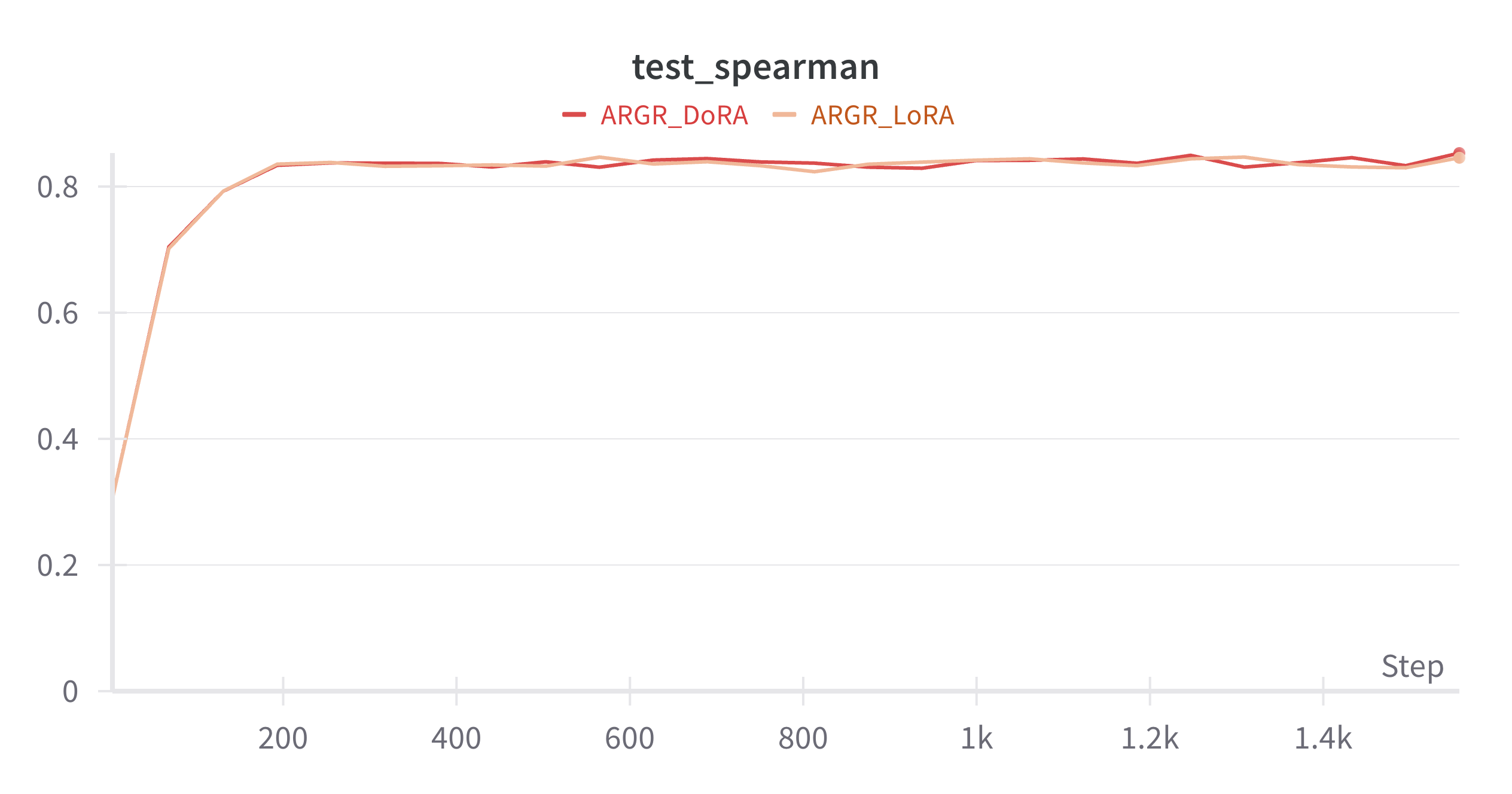
DoRA doesn’t really provide any benefit over LoRA for at least this dataset
Case Study 2: DN7A_SACS2_Rocklin_2023_1JIC: Effect of Training Data Size
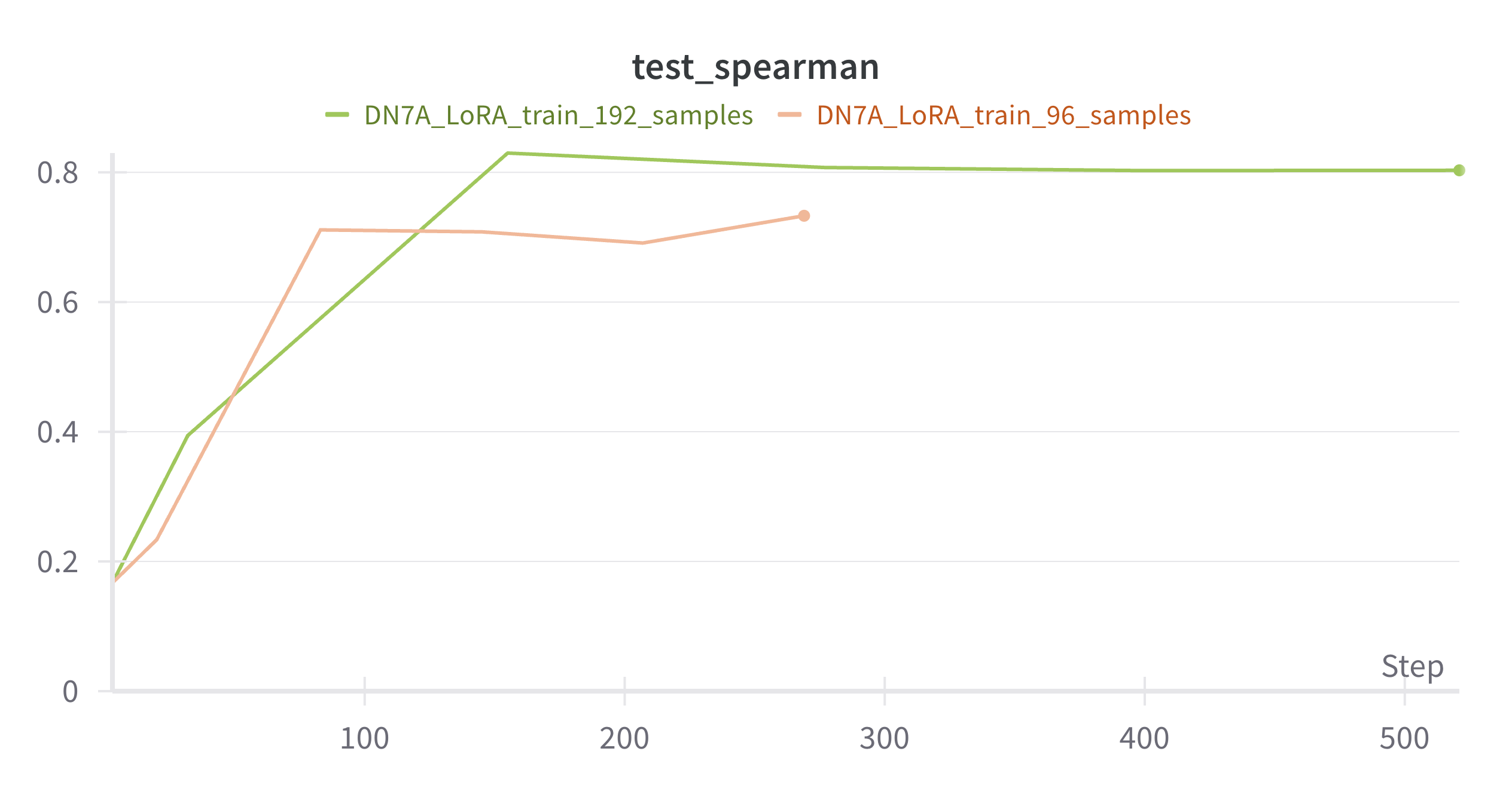
No surprises: More training data is better, but there is an asymptote that is reached pretty fast even in some cases with 196 data points (data not shown for that example here)
KCNJ2_MOUSE_Coyote-Maestas_2022_function: Lack of Regularization probably hurts
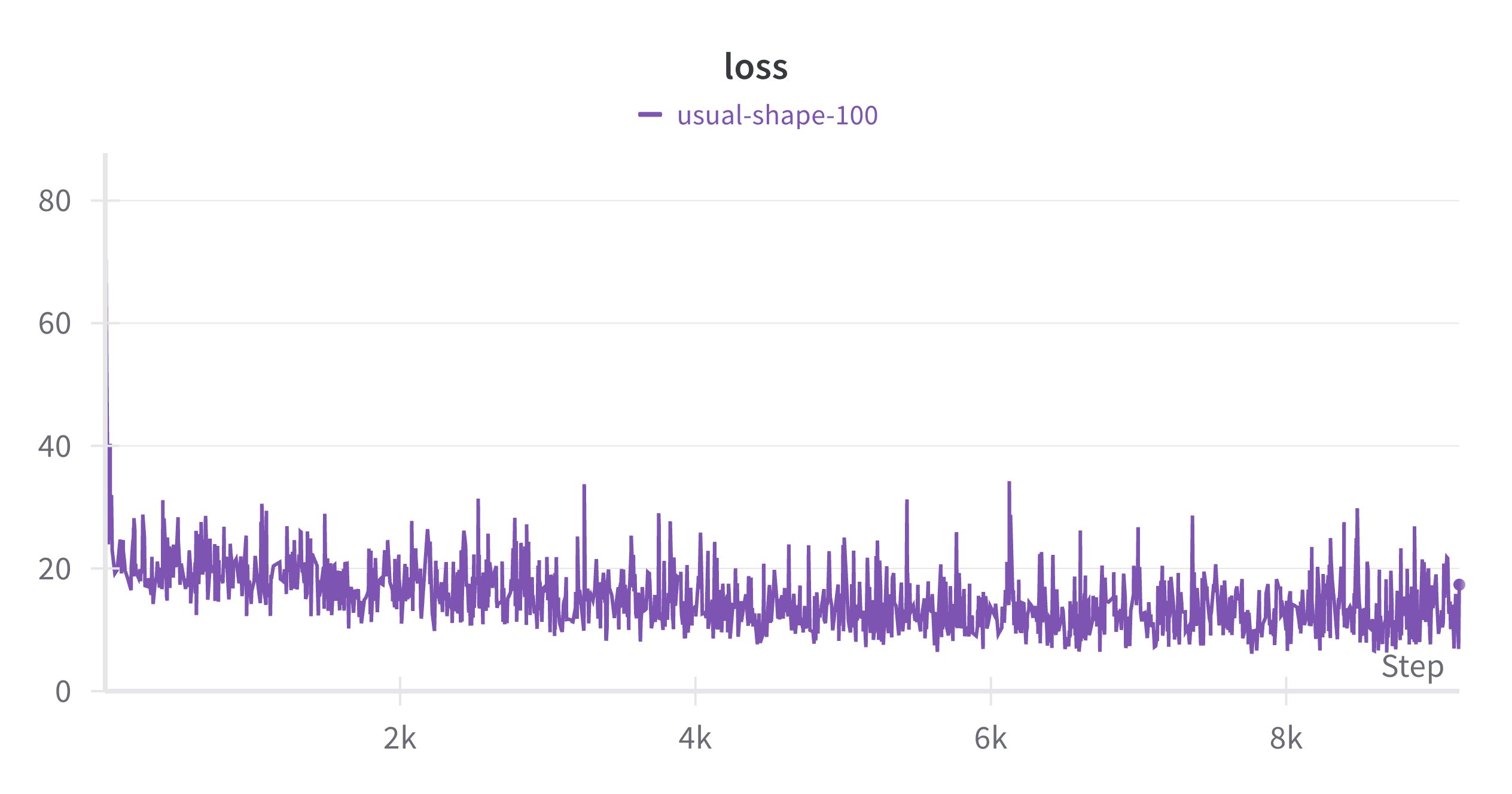
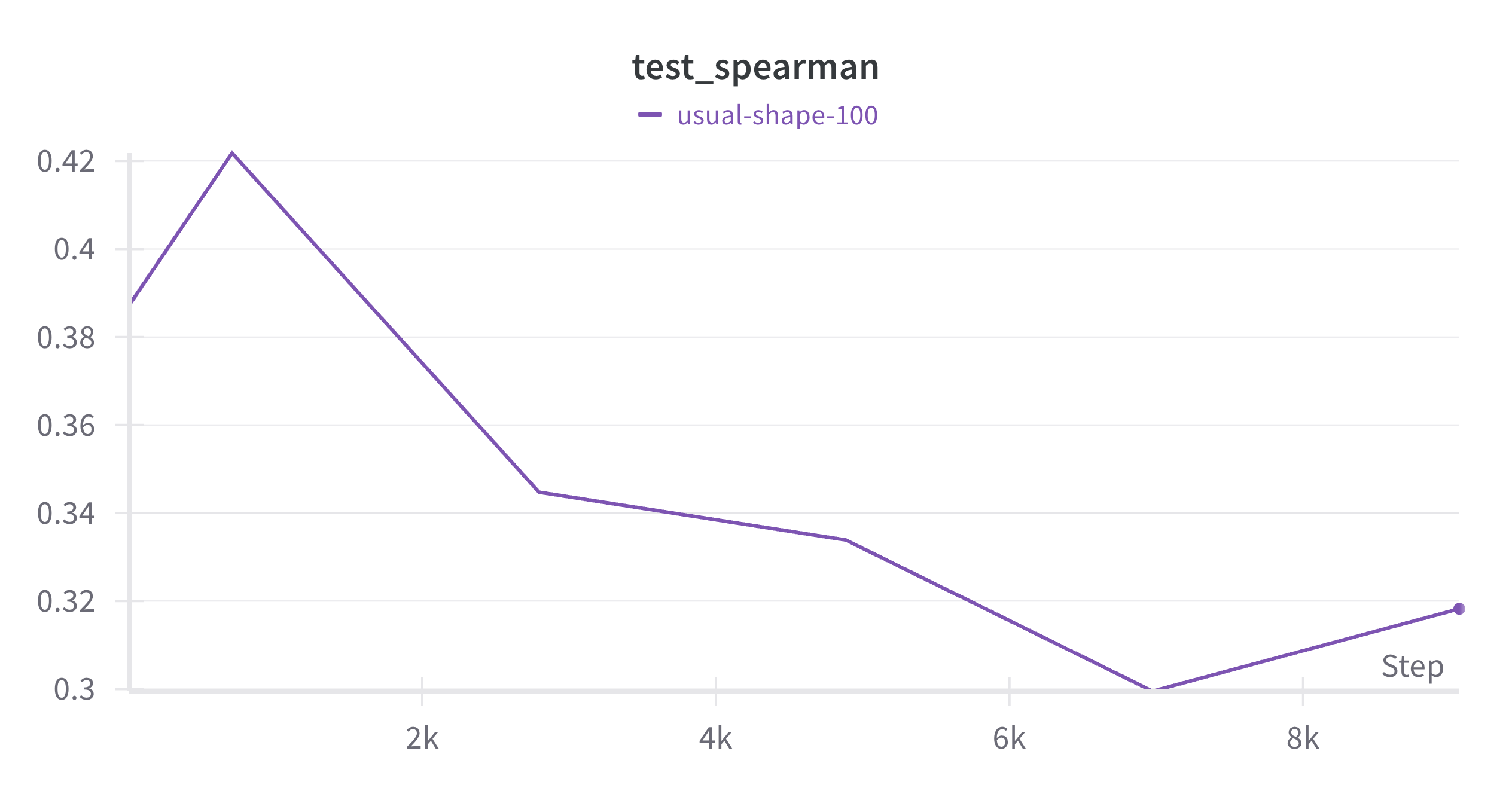
In this case, we see that the Spearman correlation for test data actually goes down with training and the final finetuned model performs worse than the original model. This could be a dataset which could benefit from regularization using the KL-divergence as shows in the ConFit paper.
There is a lot more to test on this front but the early results are encouraging!
Code to Reproduce the Above Results:
Script and repo for finetuning:
Forked ConFit repo with DiSco-CLIP loss